
A deep dive on Scaling Compute
Meet the R&D Creators looking to bring down the cost of AI hardware down by >1000x.
The history of computing hardware has been defined by scientists and engineers realising that radical new approaches are required to meet our technological needs.
From strained silicon to EUV lithography, from FinFETs to silicon photonics – each breakthrough, once deemed impractical or unattainable, became a cornerstone of our technological age. Yet the insatiable demand for more computing power made these technologies necessary and eventually foundational.
Today, we’re delighted to introduce the 12 teams of R&D Creators, who are continuing this tradition by redefining our current compute paradigm.
Identifying an unmet need
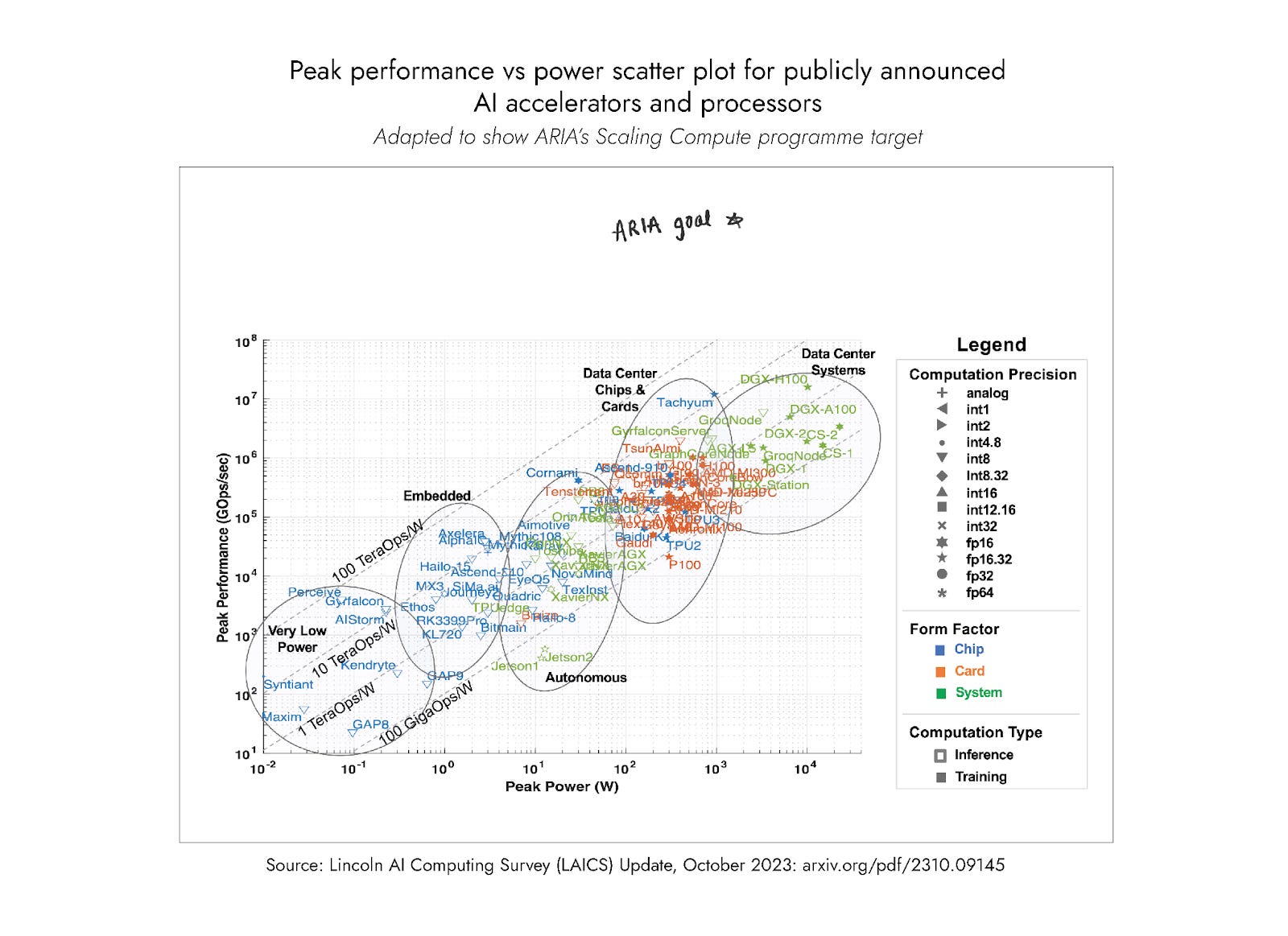
Our thesis is simple: computing progress has begun to hit a wall. The era of smaller, faster transistors, once the driving force of computing progress, is reaching its limits
This means it now costs over £100m to train the largest AI models, with this cost growing at an unsustainable rate. This has profound economic and societal implications, affecting who can build AI, what kind of AI gets built, and at what cost.
But what if we could radically reduce the cost and energy consumption of AI hardware?
Our Programme Director Suraj Bramhavar believes an opportunity lies in taking inspiration from natural systems to challenge the underlying building blocks we use to train AI systems. The target? Reducing the hardware costs required to train large AI models by >1000x.
“Unlocking one or more orders of compute, will enable a world of new applications, drastically shaping our future. This opens up opportunities to use technology for a greener future, with safer traffic, better health care... Technology and compute have never had such a profound impact on our (future) lives as today!”
- Marian Verhelst, Scaling Compute R&D Creator
Rethinking today’s computing paradigm
Breaking out from our existing paradigm requires us to think across the full stack, and develop an entirely new library of technologies. To get there, we’ll be supporting researchers across three core workstreams:
1. Charting the Course
Unsurprisingly, there isn’t an obvious answer for how we can dramatically reduce the cost and energy consumption of AI hardware, and each algorithmic advance opens up new possibilities.
To this end, we funded two projects developing software simulators which will help the research community map out the expected performance, power, and cost combination for any future combination of algorithm, hardware componentry, and system scale.
The goal is to identify where the bottlenecks are across the stack, and make it easier to keep up with rapid advances in AI algorithms.
2. Advanced Networking and Interconnect
While it's difficult to predict which specific component will be the primary bottleneck for future AI algorithms, it is well understood that the movement of data has become as critical a component as raw computational power.
That’s why we’re funding two projects which look to interrogate the system-level and advanced network design opportunities - areas that haven't received enough attention given their potential.
3. New Computational Primitives
While the computing industry continues along an established path, new approaches have emerged that harness noise, statistics, or physics in ways we haven't tried before - all using circuits we can already mass-produce.
We're funding seven teams to explore these new technologies, focusing on ones that could be especially useful for AI.
“We’re excited to push towards the fundamental limits of computational efficiency with the Scaling Compute program, by leaning into the laws of physics rather than fighting them.”
- Patrick Coles, Scaling Compute R&D Creator
Building for scale + impact
To develop a targeted programme optimised for scalable, transformative impact, we’ve made deliberate choices about where to focus our technological portfolio:
We’ve focused on large-scale, centralised AI training, since improvements here have the potential to create the most value across all AI applications.
We’ve focused on innovative uses of existing CMOS technologies , as we’ve biassed towards supporting ideas where there is a clear pathway towards manufacturing at scale.
We received many excellent proposals focused on memory materials, algorithmic architectures, and optical computing. While we couldn't fund every promising direction, these ideas present fruitful pathways to advance computing performance, and we encourage their continued pursuit.
Meet our Creators
Our Scaling Compute programme brings together broad expertise from universities, non-profits, and companies – both large and small. These researchers span three crucial domains: AI systems design, mixed-signal CMOS circuits, and advanced networking.
As well as uniting researchers in different corners of the UK, we’re delighted that the potential of this programme has served as a magnet for ambitious international organisations, with several teams committing to build and grow their technical operations in the UK.
Together, these teams represent more than just individual projects – they will serve as an invaluable talent base for the UK, bringing together the expertise, capital and networks required to pull new ideas into prototypes, and onward to real-world applications.
1. Charting the Course
Imec (led by James Myers) – Intelligently aggregating best-in-class simulation frameworks with a specific focus on AI model training while simultaneously incorporating unique knowledge of the costs associated with bleeding-edge semiconductor manufacturing.
Imperial College London / University of Edinburgh / University of Cambridge (led by Aaron Zhao, Luo Mai, + Robert Mullins) – Creating a new simulation platform using compute graphs as a unified mathematical abstraction to map modern large-scale AI models and algorithms down to the fine-grained hardware.
2. Advanced Networking and Interconnect
Alphawave Semi (led by Tony Chan Carusone) – Demonstrating novel electro-optical I/O circuitry enabling bandwidth density scaling beyond 10 Tbps/mm.
University of Oxford (led by Noa Zilberman) – Exploring system-level and network design opportunities while simultaneously tackling the manufacturing, resilience, and scalability challenges of alternative interconnect fabrics.
3. New Computational Primitives
Cornell University (led by Peter McMahon) – Designing training algorithms that can run successfully on low-precision analogue hardware initially intended for accelerating neural-network interfaces.
Fractile (led by Walter Goodwin) – Developing in-memory analog matrix multiplication arrays and harnessing reduced-precision computation for fast and efficient AI primitives.
King’s College London (led by Bipin Rajendran) – Stochastic neuromorphic encoding, low power mixed-signal circuits, and backprop-free earning algorithms for AI model development.
KU Leuven (led by Marian Verhelst) – ‘Locally-analog, globally-digital’ Ising machine circuits using CMOS bi-stable latches.
Normal Computing UK (led by Patrick Coles) – Building ‘thermodynamic computing’ units which can perform matrix inversion via networks of coupled oscillators.
Rain AI UK (led by Benjamin Scellier) – Scaling new learning algorithms based on principles of energy-minimisation and local communication to the size of modern deep learning architecture.
Rain AI UK (led by Jack Kendall) – Developing new computational primitives based on energy-minimisation in coupled resistive networks.
Signaloid (led by Phillip Stanley-Marbell) – Matrix inversion using randomised linear algebra on a hardware accelerator for probability distribution arithmetic.